
デジタル化した文書、本当に活用できている?
社内にあふれる大量の文書の中から必要な情報を探し出すことは容易ではない。
どのように文書を保管するかは人によって考え方が違う。たとえば、社内に蓄積されたナレッジを探そうとしても、ファイルサーバーへの格納方法の違いによって大切な情報が見つからないケースは少なくない。その結果、似たような文書が増えていくという悪循環に陥っているのではないだろうか。
「文書から必要な情報を取り出せないのは、フォルダ構成などの文書の格納ルールが属人的であること、つまり文書を格納する人と検索する人で格納ルールが違うことが大きな原因です」(SCSK DX技術開発センター manaBrainビジネス推進部 販売促進課 大橋 洋舟)
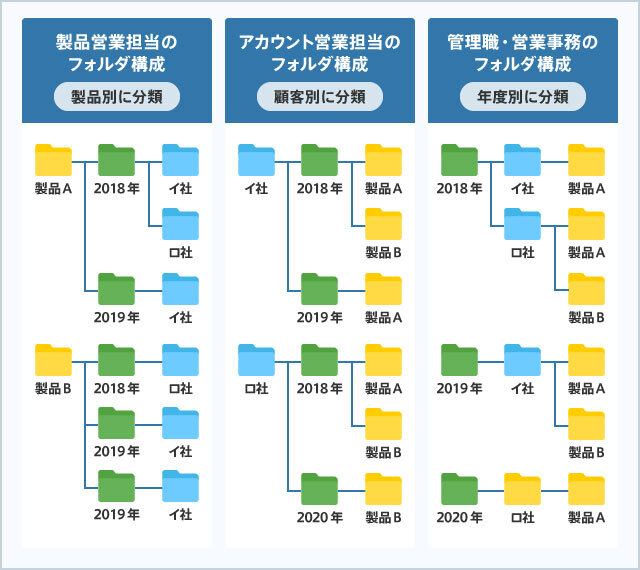
たとえば営業の現場では、同じ部門内でも格納ルールが違うこともある。製品営業は、製品別フォルダで文書を管理する。一方、アカウント営業は、顧客企業ごとに文書を管理する方が便利な筈だ。営業を管理するマネージャーや支援する営業事務は、年度単位のフォルダで管理しているかもしれない。
製品営業、アカウント営業、管理者がそれぞれのルールに基づいて文書を格納すれば、相互に有益な情報を探そうと思っても難しいだろう。
実際、「1カ月のうち丸々1日は文書探しに費やしている。何とかならないか」という相談がITベンダーにも寄せられるという。
では、文書の格納ルールを部署内で統一すればいいのだろうか。これも現実的とは言い難い。たとえば、「年度別のフォルダで文書を管理する」というルールを定めたとしよう。当初は、製品営業もアカウント営業も、決められたルールに従うかもしれない。しかし、そのうち面倒になって、各々が管理しやすいフォルダを作成するなど、ルールを統一するだけでは、文書の共有が進まない可能性があるからだ。
ショートテールとロングテールを区別して考える
統一された格納ルールがなくても、文書がデジタル化されていれば、検索で簡単に見つかるのではないかと考える人も多いかもしれない。
「エクスプローラーやGoogleドライブで文書検索すると、ヒット件数が多過ぎて、自分の求める文書がどれかを見極めるのが難しいのです」(SCSK DX技術開発センター manaBrainビジネス推進部 企画開発課長 河内 優)
そのため、フォルダ構成を頼りに文書を探すことになり、結局、属人的な文書格納ルールが妨げとなって目的の文書を探し出せなくなるという課題に直面するのだ。
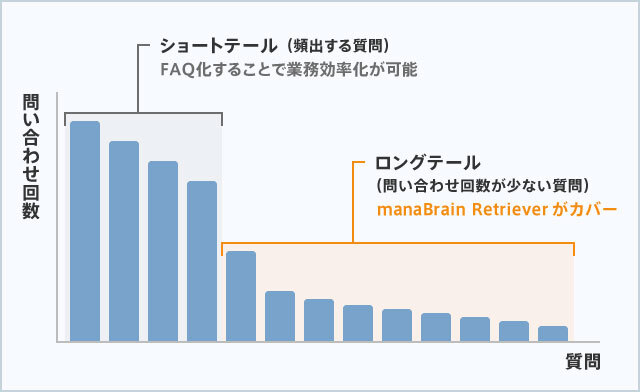
こうした課題に対しては、「アクセス頻度の高い検索や問い合わせ=ショートテール」に対する回答を、「質問-回答データベース」として用意しておくFAQというソリューションがある。
しかし、問題は「アクセス頻度の低い検索や問い合わせ=ロングテール」というニーズへの対応である。すべてに対してFAQを用意するのは難しい。コストがかかるし、そもそもすべてを網羅すること自体、不可能だ。
「社内のナレッジを共有するには、ショートテールとロングテールを区別して考えることが肝心です。そしてこれまで、ロングテールに対するソリューションはありませんでした」(大橋)
このロングテールに対するソリューションが、AIナレッジ発掘サービス「manaBrain Retriever(マナブレイン リトリーバー)」(以下、Retriever)だ。
AIを活用したナレッジ発掘が生む価値
Retrieverが提供する価値は、大きく2つある。1つ目は、企業に蓄積されたナレッジを効率よく見つけることだ。
Retrieverに文書を登録するとIBMのAIであるIBM Watson®が内容を解析し、文書にタグ付けする。そして利用者が自由な言葉で問いかけると、関連性の高い文書をタグとともに提示する。たとえば、「DXの取り組み」という言葉で探すと、提示された文書には「デジタルビジネス」「IoT」「ディスラプター」といったタグが付いているといった具合だ。
顧客の業務固有の用語に対してタグ付けを行う場合、独自にAIモデルをカスタマイズすることもできる。たとえば自動車損害保険であれば「事故の種類」や「車種」、また医療においては、カルテに記載された「症状」や「所見」をタグ付けさせるなどである。
タグ付けのルール管理と文書のタグ付けを人手で行うのは大変な労力を伴い、費用対効果もあまり期待できない。しかしAIを活用すれば、全ての文書に自動でタグを付与することができ、これまで検索やフォルダ構成では探すことが難しかったナレッジにアプローチできるようになる。「あるかどうかがわからなかったナレッジ」や「手がかりの少ないナレッジ」を見つけることも可能になるだろう。
2つ目の価値は、ナレッジをヒラメキにつなげることだ。
Retrieverが文書に紐づけて提示するタグは、「語句の属性・分類・重要度・関係性」「文章全体のトーンや意味」などの軸で分類、表示される。気になるタグをクリックすれば、タグに紐づく別の文書が現れる。タグ同士を組み合わせて関連文書を表示することも可能だ。
このように様々な気づきが喚起されたり、これまで気づかなかったナレッジにアクセスしたりすることで、新たなヒラメキが生まれるのである。これは、AIが人のような先入観にとらわれていないからかもしれない。先入観にとらわれずに付与したタグだからこそ、斬新な発想につながるのだ。
「一般的にアイデア出しには時間がかかります。外部の知恵を借りるとコストもかかります。Retrieverを活用すれば、既存のナレッジから良質なアイデアを短時間・低コストで生み出すことが可能になるのです」(河内)

(左)SCSK DX技術開発センター manaBrainビジネス推進部 企画開発課長 河内 優
(右)販売促進課 大橋 洋舟
AIによるナレッジ発掘の具体的な活用イメージ
ではここで、AIを活用したナレッジ発掘の具体的な活用イメージを見てみよう。B2Bのサービス業では、膨大なマニュアルや資料を用意しておき、個々の顧客のニーズに応じて必要なものを抽出、組み合わせ、カスタマイズして提供しているところが多い。
FAQについても同様だ。サービス全体に関する用語解説やトラブルの対処方法などを準備し、顧客が利用するサービスに応じて必要なものだけを提供している。これらの文書は、ロングテールであるケースが多く、フォルダ構成で管理したり、検索で適切な文書を探したりするのは難しいだろう。
また、製品分野別や顧客企業別の事業部門で構成されている製造業では、ナレッジも縦割りで蓄積されていて、部門横断的な共有が難しい。だが往々にして、別の部門のナレッジを取り込むことで、新しいビジネスが生まれることが多い。ある意味、こうした横串のナレッジもロングテールと捉えることができるだろう。
特に多品種少量生産の企業では、多くの文書がロングテール化しており、十分に活用できていない。こうしたナレッジにリーチできるようにするのが、Retrieverが提供する価値なのだ。
また、多言語での文書検索にも対応している。現在、Retrieverの書庫に登録できる文書は8カ国語、検索と結果の翻訳は10カ国語で可能だ。入力された自然文を書庫の言語に合わせて翻訳した上で検索できるため、海外の最新情報からナレッジを発掘することも期待できるだろう。
「法人向けのセキュアなクラウドサービス『Box』を活用しているお客様であれば、Retrieverの外部サービス連携によって、すぐにナレッジ発掘を開始できます」(河内)
人がやるべき仕事は本来、発掘したナレッジから新たな価値を生み出す(ビジネスの変革など)こと。しかし現状、ナレッジを探すことにばかり時間を取られていて、考える時間が少ない。大量の社内文書と隠れたノウハウはあるが、その価値を引き出せていないと悩んでいる企業は、まずは、スモールスタートのためのトライアル利用とそのサポートも充実しているRetrieverを試してみてはいかがだろうか。


